
Buffer Overflow es una de las mayores vulnerabilidades persistentes a pesar de la evolución y complejidad de los mecanismos de seguridad que existen hoy en día. Se encuentra presente en diversas aplicaciones por lo que aparece constantemente en las listas de vulnerabilidades críticas publicadas por instituciones enfocadas a la notificación de nuevas amenazas de seguridad.
¿Qué es un registro?
Un registro es una memoria de alta velocidad y poca capacidad, es utilizada para almacenar datos necesarios para la ejecución de un programa, además, algunos tienen funciones específicas que describiré más tarde. Pueden variar la longitud de estos dependiendo de la arquitectura del CPU (Central Processing Unit) los de 32 bits empiezan por la letra “E” y los de 64 bits empiezan por la letra “R” (nomenclatura de los registros).
Cuando un programa es ejecutado, el sistema operativo reserva una zona de la memoria para que el programa realice correctamente sus instrucciones, este espacio se dividide en zonas de acuerdo al tipo de dato que almacena y la función que realiza.
| Nombre | Nomenclatura x32 | Nomenclatura x64 | Tipo | Uso |
|---|---|---|---|---|
| Accumulator | EAX | RAX | Datos | Operaciones aritméticas |
| Base | EBX | RBX | Datos | Especifica operandos |
| Counter | ECX | RCX | Datos | Conteo de bucles en iteraciones |
| Data | EDX | RDX | Datos | Operaciones aritméticas (números grandes) |
| Source Index | ESI | RSI | Índice | Apunta al origen en operaciones en cadena |
| Target Index | EDI | RDI | Índice | Apunta al destino en operaciones en cadena |
| Base Pointer | EBP | RBP | Puntero | Almacena la dirección de memoria original del stack |
| Top Pointer | ESP | RSP | Puntero | Almacena la dirección de memoria del elemento más reciente del stack |
| Instruction Pointer | EIP | RIP | Puntero | Apunta a la dirección de memoria de la siguiente instrucción a ejecutar |
Nosotros, para explotar este Buffer Overflow vamos a quedarnos con los registros EIP/RIP y el ESP/RSP, en otras ocasiones necesitaremos otros registros pero en esta ocasión no.
¿Qué es un buffer?
Son regiones de memoria reservadas para el almacenamiento temporal de datos de entrada en un programa, están localizadas en el stack y en el heap dependiendo del tipo de dato que se quiera almacenar.
Cuando se produce un buffer overflow, los datos adicionales escritos en el búfer sobrescriben la memoria adyacente, lo que puede causar que el programa falle o que se comporta de manera impredecible. Si un atacante puede explotar esta vulnerabilidad, puede utilizar técnicas de inyección de código para ejecutar su propio código en el sistema afectado.
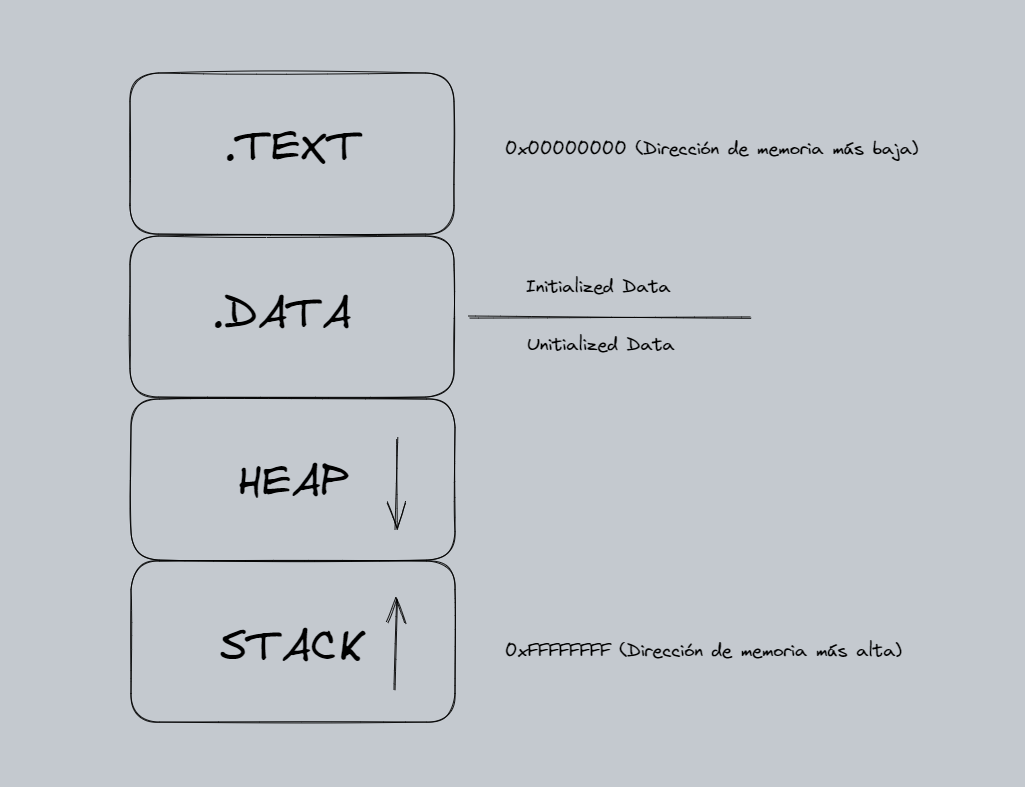 Esquema de Buffer Overflow
Esquema de Buffer Overflow
- Stack: almacena los argumentos de las funciones, las variables locales y las direcciones de retorno de las llamadas a funciones. Funciona mediante el algoritmo LIFO (Last In Firts Out), para entender este algoritmo podemos imaginar que la memoria es una caja y los datos son libros. Si nosotros metemos el libro de matemáticas, luego el de historia y por último el de lengua tendremos que sacar primero los que estan encima (historia y lengua) para luego poder sacar el último (matemáticas). Aunque parezca ilógico, cuando se almacena un nuevo valor en el stack el Top Pointer (ESP) tendrá un valor de memoria inferior, por ejemplo, antes de introducir un nuevo valor el ESP valía
0xbffff590y luego de introducirlo vale0xbffff58c. Es decir, cuando la pila crece lo hace hacia direcciones menores y cuando decrece lo hace hacia direcciones mayores. - Heap: gestiona la memoria dinámica (memoria solicitada durante la ejecución del programa), por ejemplo, utilizando las funciones malloc(), alloc() o free() entre otras. El heap funciona de forma parecida al STACK en cuanto al manejo de las direcciones de memoria, cuando el HEAP crece lo hace hacia direcciones mayores y cuando decrece lo hace hacia direcciones menores.
- Text: contiene las instrucciones ejecutables del programa, además, es un área de solo lectura para evitar que se editen estas instrucciones.
- Data: se divide en “Unintialized data” y “Intialized data”.
- Unintialized data: almacena variables globales y variables estáticas inicializadas a cero o tienen una inicialización explícita en el código, por ejemplo,
static int i;. - Initialized data: almacena datos que tienen un valor predefinido y se pueden modificar, por ejemplo,
int val = 3; char string [] = "Hola mundo";.
- Unintialized data: almacena variables globales y variables estáticas inicializadas a cero o tienen una inicialización explícita en el código, por ejemplo,
Para poder ver claramente la diferencia entre el stack y el heap podemos usar un programa de C, el código es el siguiente:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
#include <stdlib.h>
void foo(int valor) {
unsigned char c;
unsigned char *ptr = malloc(1);
printf("Stack: %p | Heap: %p\n", &c, ptr);
if(valor <= 0) return;
foo(valor - 1);
}
int main(){
foo(10);
return 0;
}
 Diferencia entre las direcciones de memoria del stack y heap
Diferencia entre las direcciones de memoria del stack y heap
Como podéis observar, en ambos casos (HEAP Y STACK) se van añadiendo datos, sin embargo, el valor de las direcciones de memoria del STACK va decrementando en cada iteración y las del HEAP va aumentando, dejo una tabla para que se vea de forma más clara:
| Estructura | Valor Hexadecimal | Valor Decimal |
|---|---|---|
| Stack | 0x7ffcdb8cef77 | 140723991932791 |
| Stack | 0x7ffcdb8cef47 | 140723991932743 |
| Stack | 0x7ffcdb8cef17 | 140723991932695 |
| Heap | 0x55798f09f2a0 | 93980579197600 |
| Heap | 0x55798f09f6d0 | 93980579198672 |
| Heap | 0x55798f09f6f0 | 93980579198704 |
Little Endian y Big Endian
Little Endian y Big Endian son dos formas diferentes de ordenar los bytes en memoria.
En un sistema Little Endian, los bytes menos significativos (el byte más pequeño) se almacenan en la dirección de memoria más baja, mientras que los bytes más significativos (el byte más grande) se almacenan en la dirección de memoria más alta. En otras palabras, el byte menos significativo de la palabra se almacena primero y el byte más significativo se almacena al final. Esto significa que al leer la palabra de izquierda a derecha, se verán primero los bytes menos significativos y luego los más significativos.
En un sistema Big Endian, los bytes más significativos se almacenan en la dirección de memoria más baja, mientras que los bytes menos significativos se almacenan en la dirección de memoria más alta. En otras palabras, el byte más significativo de la palabra se almacena primero y el byte menos significativo se almacena al final. Esto significa que al leer la palabra de izquierda a derecha, se verán primero los bytes más significativos y luego los menos significativos.
| Estructura | Byte 0 | Byte 1 | Byte 2 | Byte 3 | Completo |
|---|---|---|---|---|---|
| Little Endian | 0x78 | 0x56 | 0x34 | 0x12 | 0x78563412 |
| Big Endian | 0x12 | 0x34 | 0x56 | 0x78 | 0x12345678 |
Saber si la arquitectura del equipo que estamos intentando vulnerar utiliza little endian o big endian es muy importante, ya que si no sabemos esto los formatos de las direcciones de memoria no serán los correctos por lo que no podremos explotar el buffer overflow.
¿Qué es Buffer Overflow?
Buffer Overflow es una vulnerabilidad asociada al desbordamiento de la memoria a través de un uso excedido de esta, de ahí viene el nombre de Buffer Overflow (desbordamiento de memoria).
Cuando se produce un buffer overflow, los datos adicionales escritos en el buffer sobrescriben la memoria adyacente, lo que puede causar que el programa falle o que se comporte de manera inesperada, pudiendo llegar a causar una ejecución remota de comandos. Si un atacante puede explotar esta vulnerabilidad, puede utilizar técnicas de inyección de código para ejecutar su propio código en el sistema afectado.
Tipos de Buffer Overflow
Los 2 tipos de buffer overflow se clasifican según el espacio de memoria que se sobreescribe al momento de hacer el overflow:
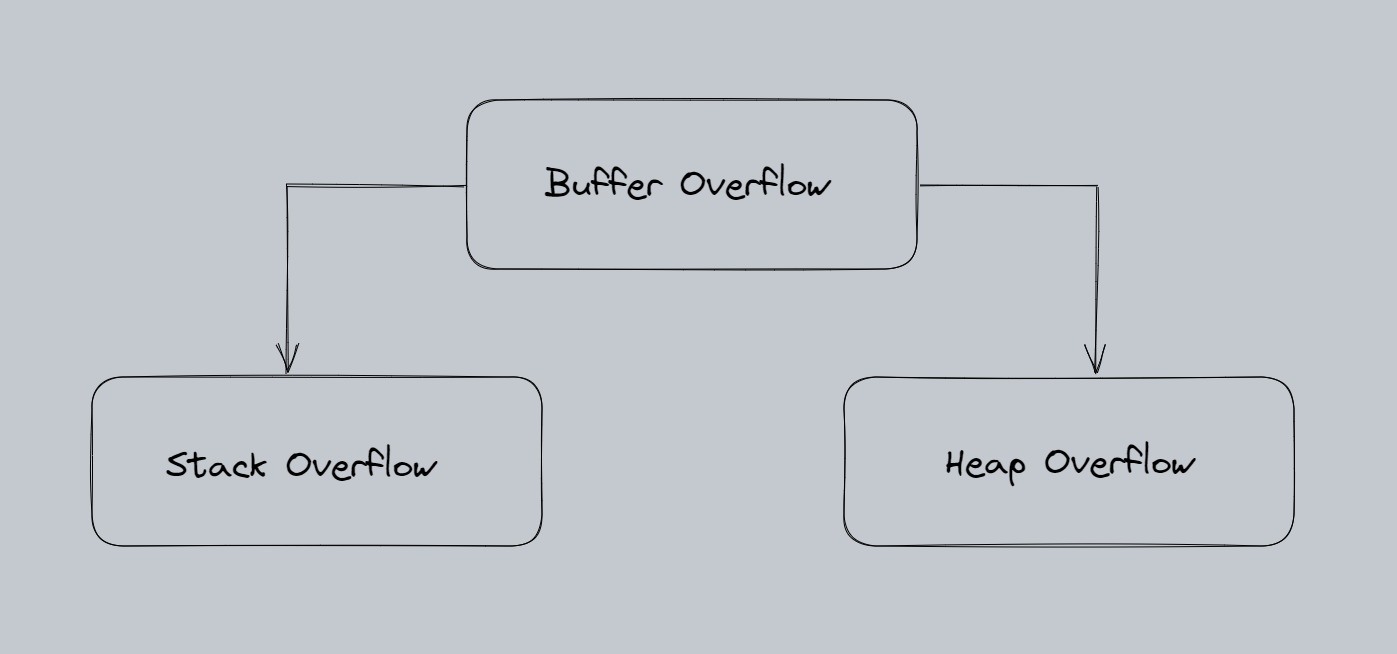 Esquema de Buffer Overflow
Esquema de Buffer Overflow
Stack Overflow: un stack overflow ocurre cuando se agota la memoria asignada para el stack de una aplicación. El stack es una región de memoria utilizada para almacenar información sobre las llamadas de funciones en una aplicación. Cuando se llama a una función, se agregan datos a al stack y cuando se regresa de la función, se eliminan los datos del stack. Si se agota la memoria asignada para el stack, se produce un desbordamiento del stack.
Heap Overflow: un heap overflow ocurre cuando se agota la memoria asignada para el heap de una aplicación. El heap es una región de memoria utilizada para almacenar datos dinámicos que se asignan y liberan durante la ejecución de una aplicación. Si se asigna más memoria de la que se ha reservado para el heap, se produce un desbordamiento del heap
Explotación de Buffer Overflow
En este post no voy a explicar como se explota un Buffer Overflow, creo no es necesario ya que hay infinitos recursos que explican esto. Por lo que para mí no tiene sentido subir un contenido repetido. Igualmente os voy a dejar algunos recursos que creo que os pueden servir para aprender a explotar uno:
- Gatogamer: Linux Stack Overflow y Windows Stack Overflow
- Deep Hacking: Fundamentos Stack Overflow
- Rapid: Stack Overflow
- LiveUnderflow: Linux Heap Overflow
Mitigación
Como he explicado, un buffer overflow puede llegar a ser muy peligroso ya que puede conllevar una ejecución remota de comandos, es por esto que es muy importante saber protegernos de este. Aquí os dejo algunos consejos para prevenirlos en vuestros programas:
- Verificar la entrada de datos: Es importante validar la entrada de datos y asegurarse de que cumple con los requisitos de formato y tamaño antes de procesarla.
- Limitar el tamaño de los datos de entrada: Si el tamaño de los datos de entrada no se puede validar, es importante limitar el tamaño del búfer de memoria asignado para la entrada de datos.
- Utilizar funciones seguras: En muchos lenguajes de programación, existen funciones seguras que se pueden utilizar en lugar de funciones inseguras que podrían causar un buffer overflow. Por ejemplo, en C, se pueden utilizar las funciones strncpy o strlcpy en lugar de strcpy.
- Implementar mecanismos de protección de memoria: Muchos sistemas operativos y lenguajes de programación ofrecen mecanismos de protección de memoria que pueden ayudar a prevenir los buffer overflows. Por ejemplo, podemos usar algunas características de seguridad como DEP, PIE y ASLR.
- Utilizar análisis de código estático y pruebas de penetración: Es importante realizar pruebas de seguridad en el código para detectar posibles vulnerabilidades, incluidos los buffer overflows. Las pruebas de penetración también pueden ser útiles para identificar vulnerabilidades y verificar si las medidas de mitigación son efectivas.